The Claims AI Problem Most Carriers Are Trying to Fix Too Late
Claims automation doesn't start downstream. It starts with trusted intake data at the first moment a claim enters the organization.
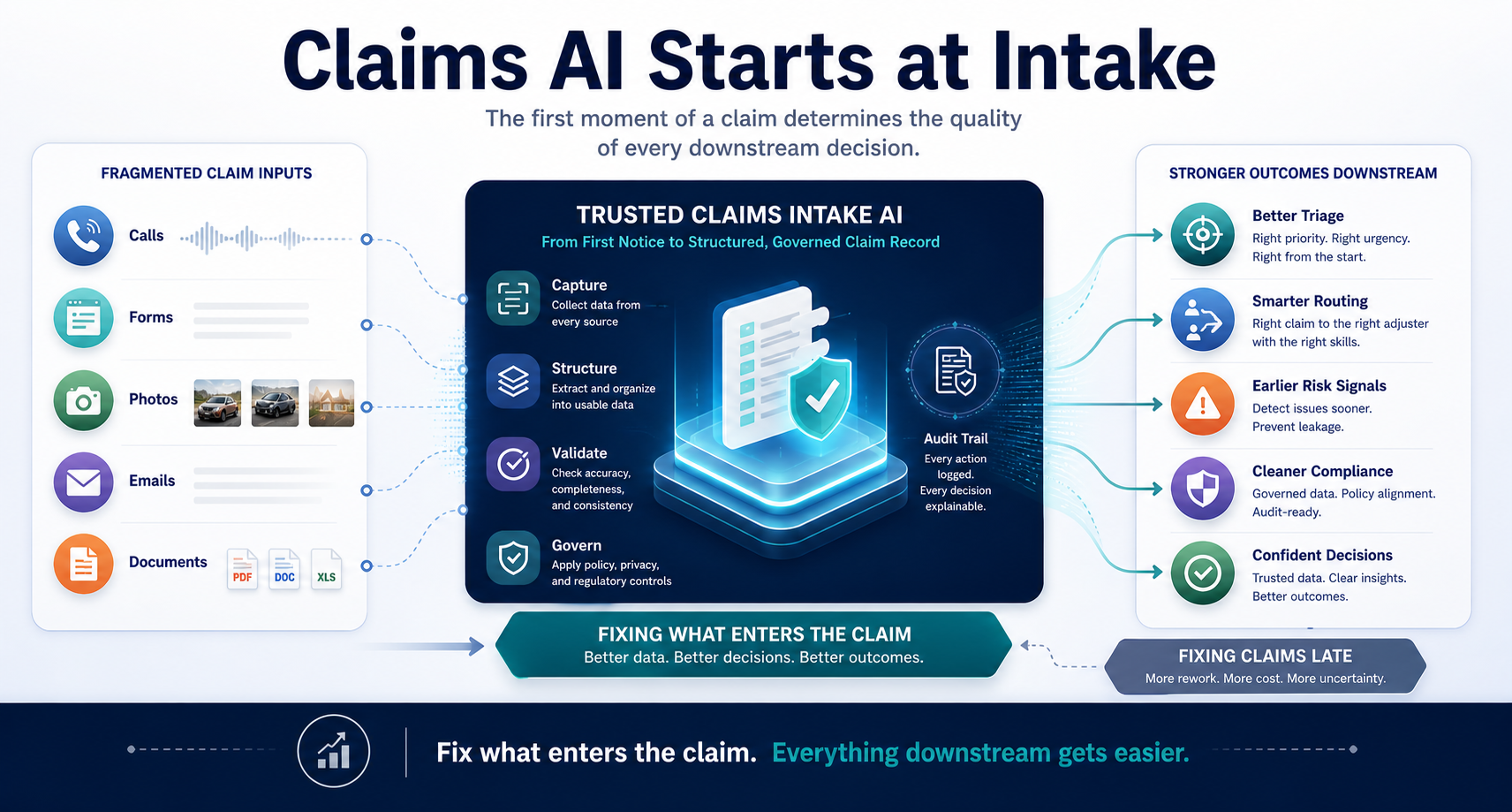
The First Moment Sets the Trajectory
Most claims transformation programs begin downstream. They look at cycle time, adjuster productivity, leakage, litigation, fraud review, customer communication, and settlement accuracy. Those are all real problems. But by the time they appear in reports, dashboards, escalation queues, or customer complaints, the claim has already been shaped by something much earlier: the quality of the information captured at intake.
The first notice of loss is often treated like an administrative step. A form is completed. A call is summarized. Photos are uploaded. Emails arrive. Documents get attached. Someone opens a file, chooses a loss type, captures a few facts, and sends the claim into motion. It looks like the beginning of a workflow, but operationally it is much more important than that. FNOL is the moment the claim record is born.
If that record is incomplete, inconsistent, unstructured, or poorly governed, everything downstream becomes harder. Triage becomes guesswork. Routing becomes reactive. Fraud review comes too late. Adjusters spend time reconstructing facts that should have been captured correctly at the start. Leaders invest in automation on top of intake data that cannot be trusted, then wonder why the results disappoint.
Claims AI fails when it tries to make confident decisions from messy inputs. The leverage is not simply adding intelligence later. The leverage is making the intake layer intelligent enough that every downstream step has a better foundation.
Bad Intake Creates Expensive Work Everywhere Else
A claim does not become complex only when it reaches a senior adjuster. The signals are usually present much earlier. Severity indicators, coverage ambiguity, missing documentation, inconsistent loss descriptions, injury mentions, prior claim patterns, suspicious timing, repair complexity, jurisdictional issues, and specialist-handling needs often show up in the first call, the first form, the first document, or the first batch of photos.
The problem is that most carriers do not consistently extract and structure those signals at the point of entry. Some information is buried in notes. Some is trapped in PDFs. Some appears in emails or attachments that are never compared against the original claim description. Some is captured differently by different intake representatives. Some is technically present but not usable by rules, models, supervisors, auditors, or downstream systems.
That creates a quiet operational tax. Claims are routed incorrectly, then rerouted. Simple claims wait behind complex ones. Complex claims are treated as simple until someone discovers the issue days later. Fraud teams receive referrals after the claim has already developed momentum. Adjusters lose time chasing missing information. Compliance teams struggle to explain why a decision was made, who saw what, and when.
This is why faster claims automation can become a trap. Speed applied to bad intake does not create control. It accelerates uncertainty. A carrier can automate tasks, generate summaries, and move files faster, but if the core claim record is weak, the organization is still operating from a compromised version of reality.
Documents Are Not Attachments
One of the biggest intake blind spots is document handling. In many claims operations, documents are treated as attachments to the claim file rather than decision data inside the claim file. That distinction matters.
A police report, estimate, medical bill, repair invoice, proof of ownership, demand letter, or prior correspondence can contain information that changes severity, routing, liability, coverage, fraud risk, or required handling. But if the document is simply uploaded and stored, its contents remain trapped until a human opens it, reads it, interprets it, and manually transfers the relevant facts into the claim workflow.
Trusted claims intake AI changes the role of documents. It extracts the data, validates it against the claim record, structures it into usable fields, compares it against other sources, flags inconsistencies, and preserves an audit trail of what was found. That does not remove human judgment. It gives human judgment a better starting point.
A document should not be a black box sitting in the file. It should be part of the claim's operational memory. When documents become searchable, comparable, explainable, and auditable, carriers gain a more complete view of the claim much earlier. That early clarity compounds. It improves triage, adjuster assignment, fraud detection, compliance review, and decision confidence.
Triage Is Only as Good as the Intake Data Feeding It
Many carriers want smarter triage. That instinct is right. The claims organization should know which files can move quickly, which need specialist review, which require immediate customer contact, which present potential fraud indicators, and which carry complexity that should not be discovered late.
But triage is not a standalone intelligence layer. It is an output of intake quality. If the intake process misses key facts, fails to structure them, or cannot reconcile information across channels, even the best triage logic is limited. It may appear sophisticated, but it is still making decisions from partial evidence.
This is especially important for mid-market carriers. Large carriers may have the budget to build internal AI teams, custom platforms, long-running data programs, and extensive analytics layers. Mid-market carriers usually do not have that luxury. They need practical operational leverage without spending years assembling infrastructure before value appears.
That makes the intake layer the natural place to focus. It is close to the work. It touches every claim. It can improve outcomes without requiring the carrier to rebuild the entire claims organization at once. When intake captures, structures, validates, and governs information properly, downstream teams feel the difference quickly. Claims arrive cleaner. Adjusters start with better context. Supervisors see risk earlier. Compliance has a clearer record. The organization spends less energy correcting preventable uncertainty.
Trust Is the Operating Requirement
Insurance claims are not a casual AI use case. Decisions affect customers, reserves, payments, compliance obligations, litigation exposure, and regulatory scrutiny. That means the category cannot be generic AI for claims. The real category is trusted claims intake AI.
Trusted AI does not mean the system is always right. It means the system is designed so its work can be inspected, challenged, corrected, and governed. It detects sensitive information. It masks what should be masked. It applies policy gates. It shows why something was flagged. It logs what was extracted, where it came from, how it was used, and who reviewed it. It helps carriers move faster without losing control.
That is the difference between automation that creates confidence and automation that creates risk. Claims leaders do not simply need more AI activity inside the workflow. They need a governed intake layer that turns fragmented claim inputs into a reliable operational record.
The future of claims automation will not be won by the carrier that adds the most AI features across the workflow. It will be won by the carrier that owns the first moment with the most discipline. From first notice to confident decision, the claim depends on the quality of the record. And the record begins at intake.